アテンション機構付きの seq2seq モデルで機械翻訳する(PyTorch チュートリアル)¶
参考文献の 1 つ目のチュートリアルをやります。コードの順序を前後させていたりデバッグプリントを入れていることがあります。自分の誤りは自分に帰属します。何か問題がありましたら以下からご連絡いただけますと幸いです。
https://github.com/CookieBox26/ToyBox/issues
参考文献¶
- NLP FROM SCRATCH: TRANSLATION WITH A SEQUENCE TO SEQUENCE NETWORK AND ATTENTION
- 本記事でなぞるチュートリアル。seq2seq モデルでフランス語を英語に機械翻訳する。
- [1409.3215] Sequence to Sequence Learning with Neural Networks
- チュートリアル中の随所の sequence to sequence network という文字列からリンクがある論文。この論文では英仏翻訳している。
- フランス語の否定文 - Wikipedia
- 「ne ... pas に代表されるように否定が ne を含む 2 語で表される」(ことからも仏英翻訳は単語を単語に翻訳すればいいのではないことがわかる)。
- [1406.1078] Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation
- これもチュートリアル冒頭で2回繰り返し紹介されている論文。この論文で GRU が提案、導入された。
- [1409.0473] Neural Machine Translation by Jointly Learning to Align and Translate
- これもチュートリアル冒頭で2回繰り返し紹介されている論文。
目次
データの準備
 |
このチュートリアルではフランス語を英語に機械翻訳するんですね。フランス語がわからないので結果がすごいのかすごくないのかわかりにくそうですが…自分がわかる言語にカスタマイズしてみるのはまずチュートリアルをなぞった後の方がよさそうですね。素直に https://download.pytorch.org/tutorial/data.zip から data/eng-fra.txt をダウンロードします。135842 行ありますね。早速中身をみてみましょう。 |
In [1]:
print('◆ データの冒頭')
with open('./data/eng-fra.txt', mode='r') as ifile:
for i, line in enumerate(ifile):
if i == 10:
break
print(line.strip())
|
…ファイルは1語文から始まって徐々に語数の多い文章になっているようですが、Run! や Stop! に対応するフランス語文が複数あるのが気になりますね…。まあいいです、それで、各単語を one-hot ベクトルにするんですね。今回のチュートリアルでは各言語ごとに語彙を数千単語のみに絞るようです。「ちょっとごまかします」とあるように、現実的には単語数はこれでは足りないということですね。one-hot ベクトル化する前に各文章をプレ処理するんですが(以下)、やることとしては「小文字化」「アスキーコード化」「句点と感嘆符と疑問符の切り離し」「アルファベットと句点と感嘆符と疑問符以外の除去」でしょうか。…最終的に単語ベクトルを使用するのならば、文字種をアスキーに限定する必要があるんでしょうか? まあどうでもいいですが…。 |
In [2]:
import unicodedata
import re
# ユニコード文字集合をアスキー文字集合だけで表現する関数
# ここでは、元文字列の各文字を NFD という正規化形式で分解することで
# アクセント記号を分離し、アクセント記号は除去する
# 元コメント:
# Turn a Unicode string to plain ASCII, thanks to
# https://stackoverflow.com/a/518232/2809427
def unicodeToAscii(s):
return ''.join(
c for c in unicodedata.normalize('NFD', s)
if unicodedata.category(c) != 'Mn'
)
# 小文字化、アスキーコード化、句点と感嘆符と疑問符の切り離し、記号除去する関数
def normalizeString(s):
s = unicodeToAscii(s.lower().strip()) # 小文字化、アスキーコード化
s = re.sub(r"([.!?])", r" \1", s) # 任意の文字に続く . ! ? の前に空白を挟む
s = re.sub(r"[^a-zA-Z.!?]+", r" ", s) # アルファベット . ! ? 以外は除去
return s
print('◆ データの冒頭にプレ処理を適用')
with open('./data/eng-fra.txt', mode='r') as ifile:
for i, line in enumerate(ifile):
if i == 10:
break
pair = line.strip().split('\t')
print('-'*30)
print('オリジナル ', pair[0], '\t', pair[1])
print('ASCII文字化 ', unicodeToAscii(pair[0]), '\t', unicodeToAscii(pair[1]))
print('記号トリム ', normalizeString(pair[0]), '\t', normalizeString(pair[1]))
|
そして今回は簡単のために、全ての文章を学習するのではなく、「10単語未満」「特定のフレーズで始まる」文章に絞るようですね。 |
In [3]:
# 今回は10単語未満の文章に絞る
MAX_LENGTH = 10
# 今回は英文側が以下のフレーズで始まる文章に絞る
eng_prefixes = (
"i am ", "i m ",
"he is", "he s ",
"she is", "she s ",
"you are", "you re ",
"we are", "we re ",
"they are", "they re "
)
def filterPair(p):
return len(p[0].split(' ')) < MAX_LENGTH and \
len(p[1].split(' ')) < MAX_LENGTH and \
p[1].startswith(eng_prefixes)
# 文章ペアのリストをフィルタする関数
def filterPairs(pairs):
return [pair for pair in pairs if filterPair(pair)]
|
ここまでで用意した関数を利用してデータを生成する処理が以下ですね。まずすべての文章ペアをロードし、対象の文章ペアに絞り込んだ上で、全ての単語の頻度をカウントしながらインデックスをふっています。 |
In [4]:
SOS_token = 0
EOS_token = 1
# ある語の語彙を管理するクラス
# 文章を流し込んでいくことで単語にインデックスをふり各単語の頻度もカウントする
class Lang:
def __init__(self, name):
self.name = name
self.word2index = {}
self.word2count = {}
self.index2word = {0: "SOS", 1: "EOS"}
self.n_words = 2 # Count SOS and EOS
def addSentence(self, sentence):
for word in sentence.split(' '):
self.addWord(word)
def addWord(self, word):
if word not in self.word2index:
self.word2index[word] = self.n_words
self.word2count[word] = 1
self.index2word[self.n_words] = word
self.n_words += 1
else:
self.word2count[word] += 1
# X語 Y語 のタグ区切り文章ペアがあるファイルから文章を正規化しながら読み取り、
# 文章ペアのリストを取り出す関数
# 順序を Y語 X語 に入れ替えて取り出すこともできる
def readLangs(lang1, lang2, reverse=False):
lines = open('./data/%s-%s.txt' % (lang1, lang2), encoding='utf-8').\
read().strip().split('\n')
pairs = [[normalizeString(s) for s in l.split('\t')] for l in lines]
if reverse:
pairs = [list(reversed(p)) for p in pairs]
input_lang = Lang(lang2)
output_lang = Lang(lang1)
else:
input_lang = Lang(lang1)
output_lang = Lang(lang2)
return input_lang, output_lang, pairs
# ファイルから文章を読み込み、対象の文章にフィルタし、語彙を作成
def prepareData(lang1, lang2, reverse=False):
input_lang, output_lang, pairs = readLangs(lang1, lang2, reverse) # ファイルから文章取得
print("%s ペアを読み込みました" % len(pairs))
pairs = filterPairs(pairs) # 10単語未満で特定のフレーズから始まる文章に絞り込み
print("%s ペアに絞り込みました" % len(pairs))
# 語彙作成
for pair in pairs:
input_lang.addSentence(pair[0])
output_lang.addSentence(pair[1])
print("単語数は以下でした")
print(input_lang.name, input_lang.n_words)
print(output_lang.name, output_lang.n_words)
return input_lang, output_lang, pairs
input_lang, output_lang, pairs = prepareData('eng', 'fra', True)
In [5]:
print('◆ データの冒頭')
for i, pair in enumerate(pairs):
if i == 10:
break
print(pair)
|
データが用意できましたが、これは単に文章のペアたちですから PyTorch の機械学習モデルに入れることはできませんね。単語に split して各単語をインデックスに直して PyTorch のテンソルにする必要があります。そのための関数を先に用意しておきましょう。文末には文末トークンを付けるようですね。 |
In [6]:
import torch
def indexesFromSentence(lang, sentence):
return [lang.word2index[word] for word in sentence.split(' ')]
def tensorFromSentence(lang, sentence):
indexes = indexesFromSentence(lang, sentence)
indexes.append(EOS_token)
return torch.tensor(indexes, dtype=torch.long, device='cpu').view(-1, 1)
def tensorsFromPair(pair):
input_tensor = tensorFromSentence(input_lang, pair[0])
target_tensor = tensorFromSentence(output_lang, pair[1])
return (input_tensor, target_tensor)
print('◆ 生データ')
print(pairs[0])
(input_tensor, target_tensor) = tensorsFromPair(pairs[0])
print('\n◆ インプットデータ')
print(input_tensor.size())
print(input_tensor)
print('\n◆ ターゲットデータ')
print(target_tensor.size())
print(target_tensor)
seq2seq モデル
|
肝心のモデルの話に入っていきますね。ここでは seq2seq モデルといって、エンコーダの RNN とデコーダの RNN をもつモデルを採用するのでしょうか。エンコーダが入力された文章を1つの特徴ベクトル(コンテクストベクトル)に変換し、デコーダがそれを出力文章に変換するようです。エンコードした特徴の空間の1点1点が入力された文章の「意味」なのだというようにもありますね。…というかこのようなモデルを seq2seq モデルというのですね。てっきり入力も出力もシーケンスなら何でも seq2seq モデルとよぶのかと。 |
 |
チュートリアルが Sequence to Sequence network からリンクしているのは以下の論文だね。 2014年の論文で、シーケンスをシーケンスにマッピングする汎用的なアプローチを提案すると。具体的には、入力シーケンスを多層LSTMで特徴ベクトルにエンコードし、それをまた別の多層LSTMで出力シーケンスにデコードするみたい。 |
|
はあ。その seq2seq モデルの方が RNN より機械翻訳に適しているとありますね。翻訳は単語を受け取る度に単語を出すという類のものではないからです。フランス語と英語では chat noir と black cat のように形容詞の位置も違いますし、それにフランス語には ne/pas 構造もありますし…ne/pas 構造とは? |
|
フランス語の否定文は、多くの言語と違って、動詞を ne と pas で挟むみたいだね。 だから必然的に単語数自体がずれる。先の前置修飾と後置修飾の違いもあるし、特に英仏翻訳では seq2seq モデルが適しているのかもしれない。 |
|
ええ…フランス語は否定文の形式が変わっているんですね…しかしその記事の言語学的なサイクルは理解できるような。当初は動詞の前に否定表現を付けて、強調のために動詞の後にも否定表現を付けて、やがて後者のみが残るという。まあそれで、そのように翻訳というのはまず入力文を全て読み取った後出力文にするのがよいので、エンコーダとデコーダを構築するわけですが、エンコーダとデコーダに含まれている GRU なる層は何でしょう? |
|
チュートリアル冒頭で紹介があった以下の論文で導入されていて、LSTMより少しシンプルになっている再帰ニューラルネットワークだね。LSTM よりも自由度は少ないけどタスクの種類やデータサイズによってはLSTMと同等かそれ以上の性能が見込めるみたい。 もっとも、torch.nn.GRU は Fully Gated Unit なんだけど arxiv:1406.1078 の定式化とは少し違っている。後の論文で改良されたとかかな? 参考文献がなかったからわからないや。 |
|
シンプルにしたLSTM? いや確かに LSTM よりすっきりしていますが、記憶セル c がないんですね。むしろ出力 h とされているものが記憶セルに近そうな…。 |
vanilla RNN と LSTM
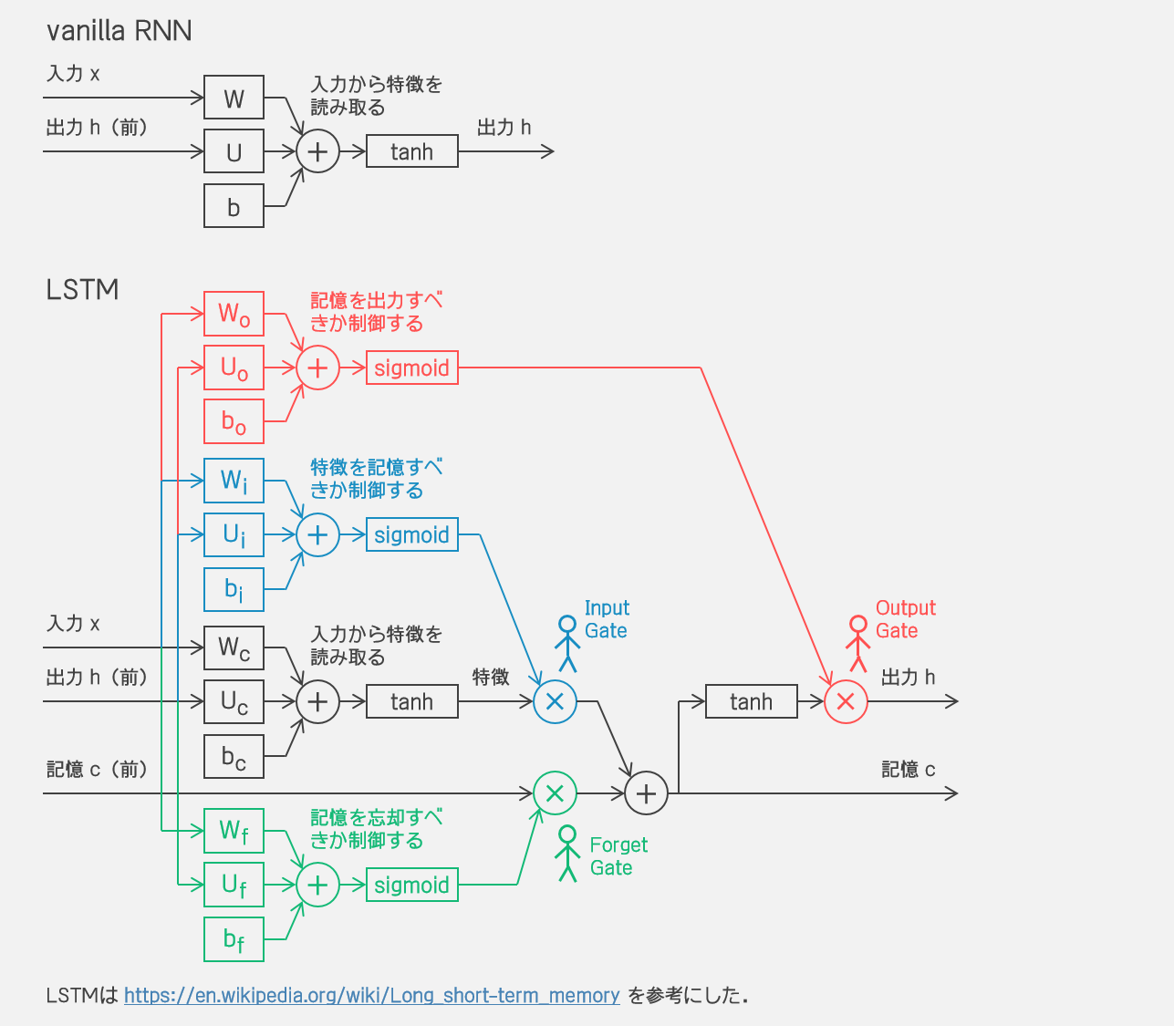
GRU
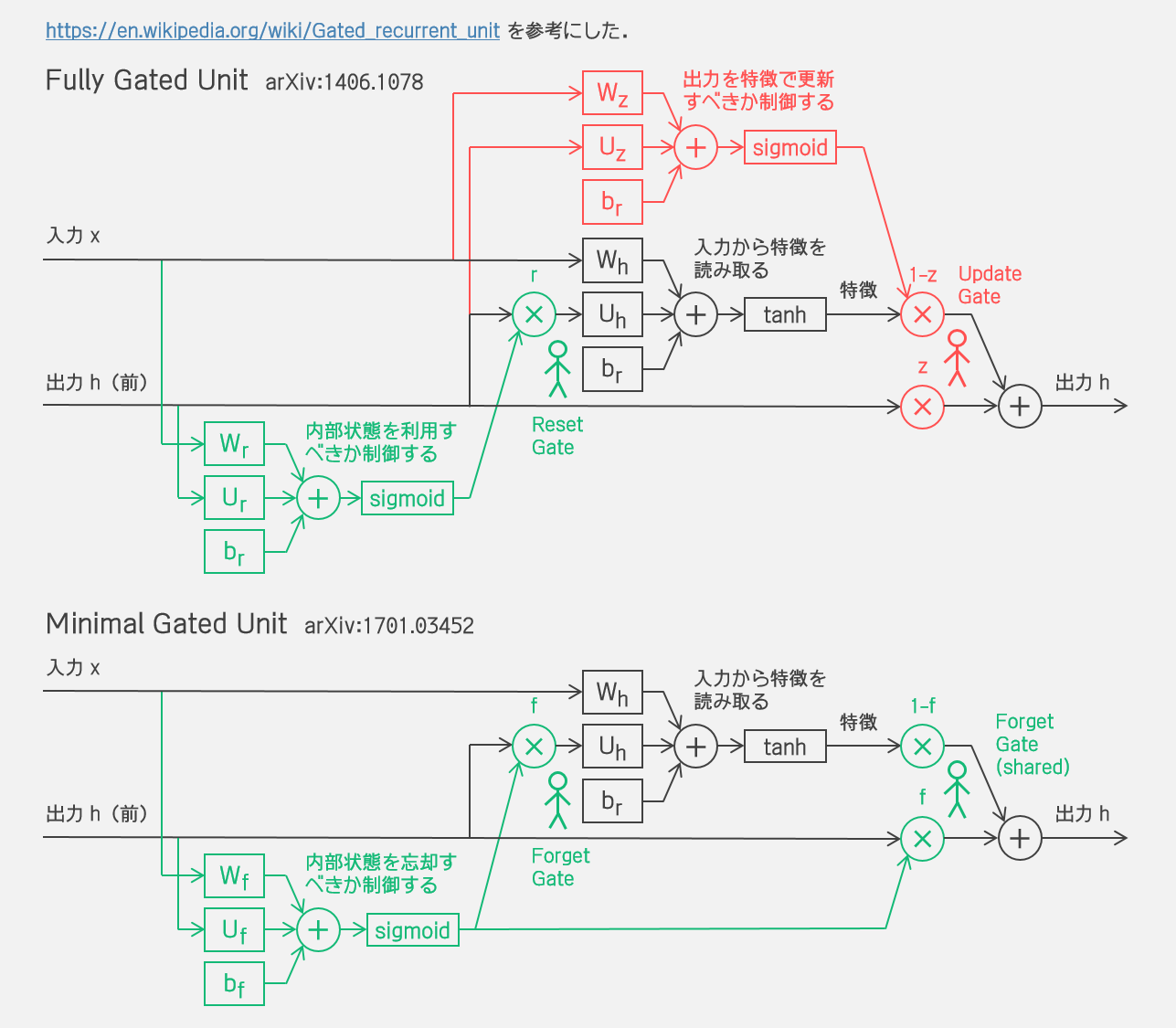
torch.nn.GRU
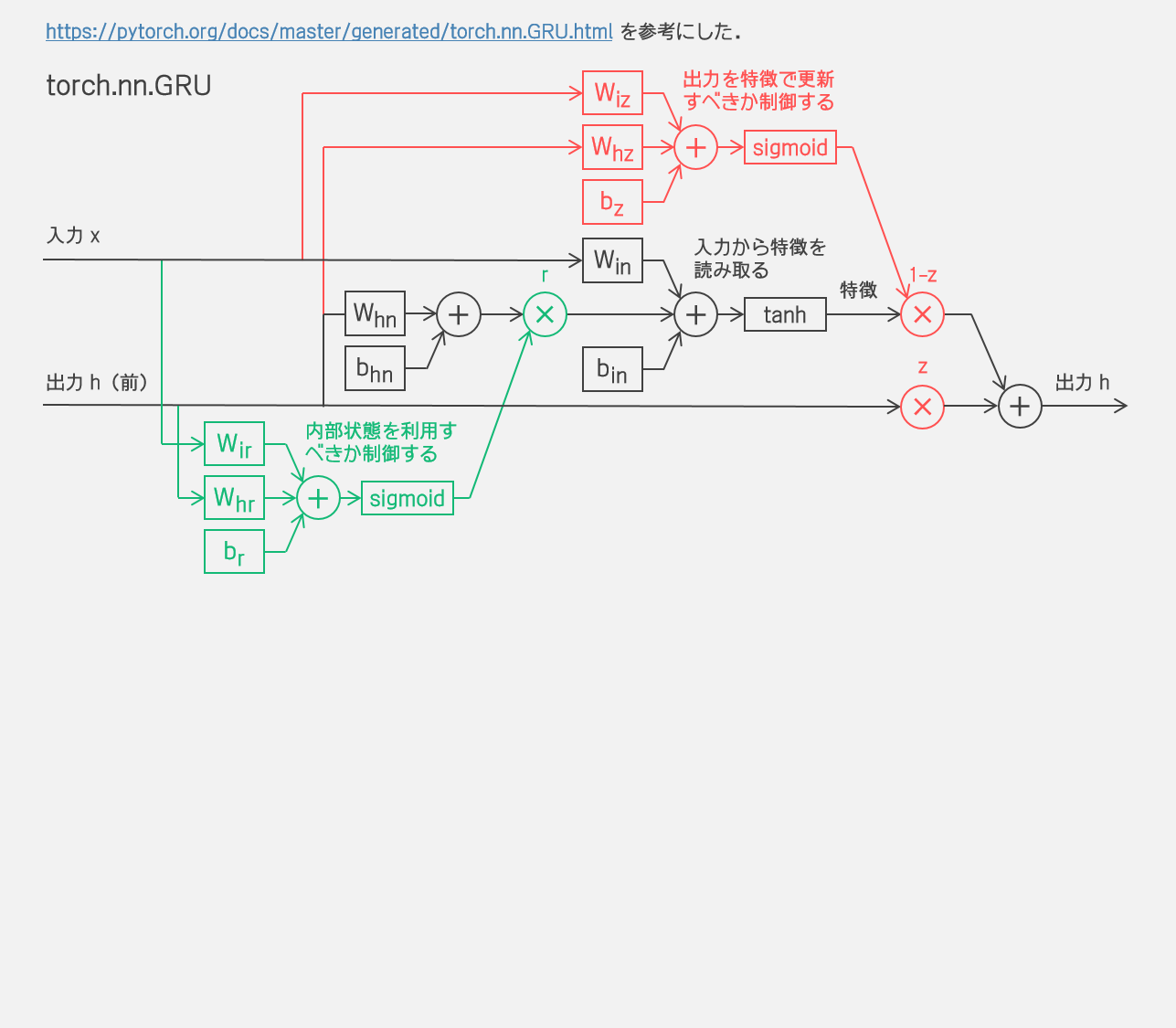
|
…まあそれで、エンコーダとデコーダは具体的には以下のコードですね。単語インデックスを高次元に埋め込んで GRU するだけです。エンコード時は特徴をどんどん積み重ねていき、デコード時は特徴をどんどん紐解いていくとイメージすればよいのでしょうか。コードの下に図も描いておきました。 |
In [7]:
import torch.nn as nn
from torch import optim
import torch.nn.functional as F
class EncoderRNN(nn.Module):
def __init__(self, input_size, hidden_size):
super(EncoderRNN, self).__init__()
self.hidden_size = hidden_size
self.embedding = nn.Embedding(input_size, hidden_size)
self.gru = nn.GRU(hidden_size, hidden_size)
def forward(self, input, hidden, debug=False):
if debug:
print('入力単語: ', input.size(), input)
print('入力特徴: ', hidden.size(), hidden[:,:,:3])
embedded = self.embedding(input).view(1, 1, -1)
if debug:
print('埋め込み後 : ', embedded.size(), embedded[:,:,:3])
output = embedded
output, hidden = self.gru(output, hidden)
if debug:
print('GRUの出力 : ', output.size(), output[:,:,:3])
print('GRUの隠れ状態: ', hidden.size(), hidden[:,:,:3])
print('(単語を1つずつ流しているので出力と隠れ状態は一致)')
return output, hidden
def initHidden(self):
return torch.zeros(1, 1, self.hidden_size, device='cpu')
class DecoderRNN(nn.Module):
def __init__(self, hidden_size, output_size):
super(DecoderRNN, self).__init__()
self.hidden_size = hidden_size
self.embedding = nn.Embedding(output_size, hidden_size)
self.gru = nn.GRU(hidden_size, hidden_size)
self.out = nn.Linear(hidden_size, output_size)
self.softmax = nn.LogSoftmax(dim=1)
def forward(self, input, hidden, debug=False):
if debug:
print('入力単語: ', input.size(), input)
print('入力特徴: ', hidden.size(), hidden[:,:,:3])
output = self.embedding(input).view(1, 1, -1)
output = F.relu(output)
output, hidden = self.gru(output, hidden)
if debug:
print('GRUの出力 : ', output.size(), output[:,:,:3])
print('GRUの隠れ状態: ', hidden.size(), hidden[:,:,:3])
print('(単語を1つずつ流しているので出力と隠れ状態は一致)')
output = self.softmax(self.out(output[0]))
if debug:
print('最終出力 : ', output.size(), output[:,:3])
return output, hidden
def initHidden(self):
return torch.zeros(1, 1, self.hidden_size, device='cpu')
hidden_size = 256
encoder = EncoderRNN(input_lang.n_words, hidden_size).to('cpu')
decoder = DecoderRNN(hidden_size, output_lang.n_words).to('cpu')
print('◆ エンコーダの訓練対象パラメータ')
for name, param in encoder.named_parameters():
print(name.ljust(14), param.size())
print('\n◆ デコーダの訓練対象パラメータ')
for name, param in decoder.named_parameters():
print(name.ljust(14), param.size())
エンコーダとデコーダ
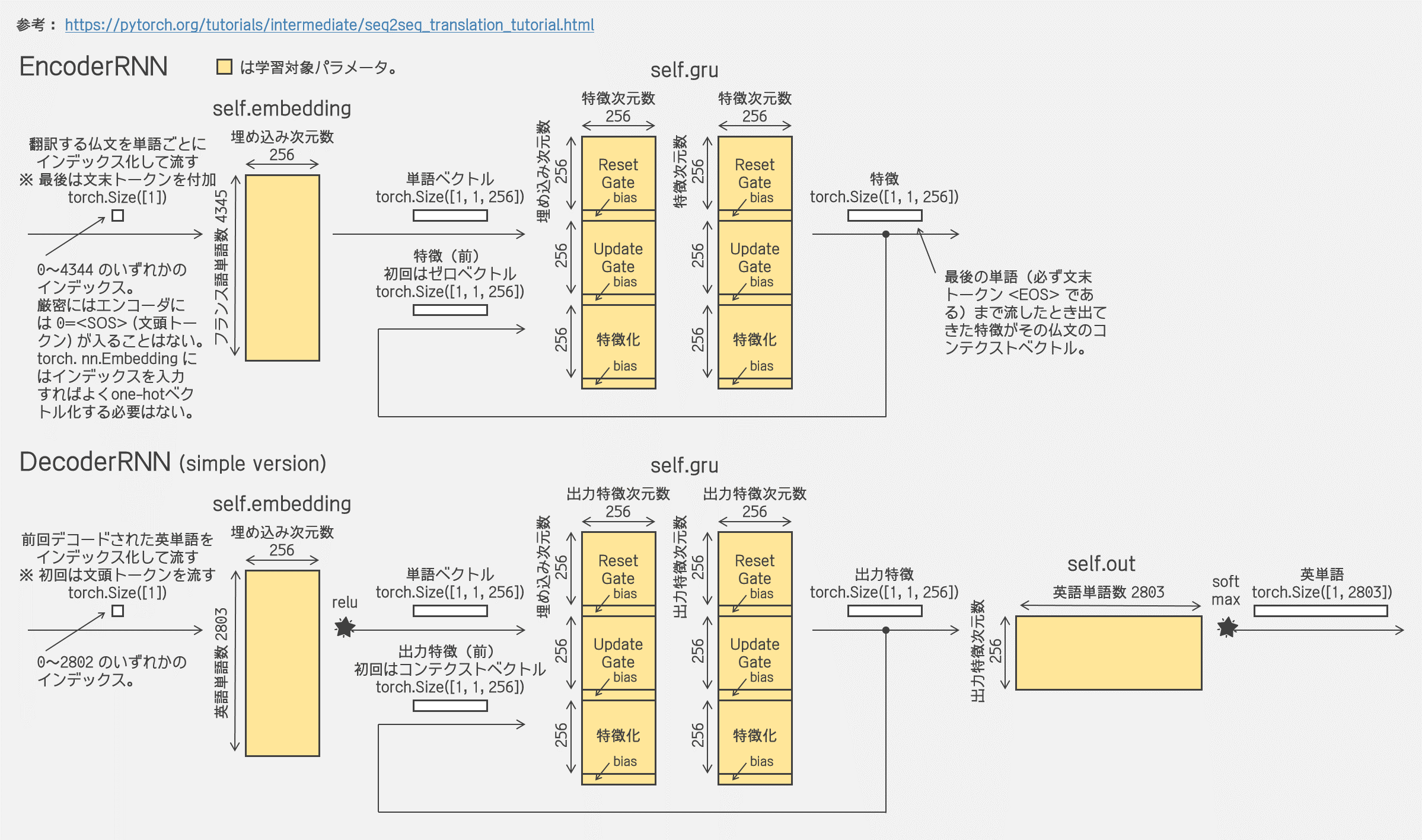
|
仏英翻訳だから、エンコーダにはフランス語の文章を1単語ずつ入れていくことになるね。1単語入れる度にエンコーダから特徴が出力される。1つの文章を入れ終わった最終的な特徴がコンテクストベクトルだね。コンテクストが得られたら、デコーダに文頭トークンとコンテクストベクトルを入れることで1語ずつ単語を取り出す。文末トークンが出てきたらデコードは終了って感じなのかな。 |
翻訳の流れ
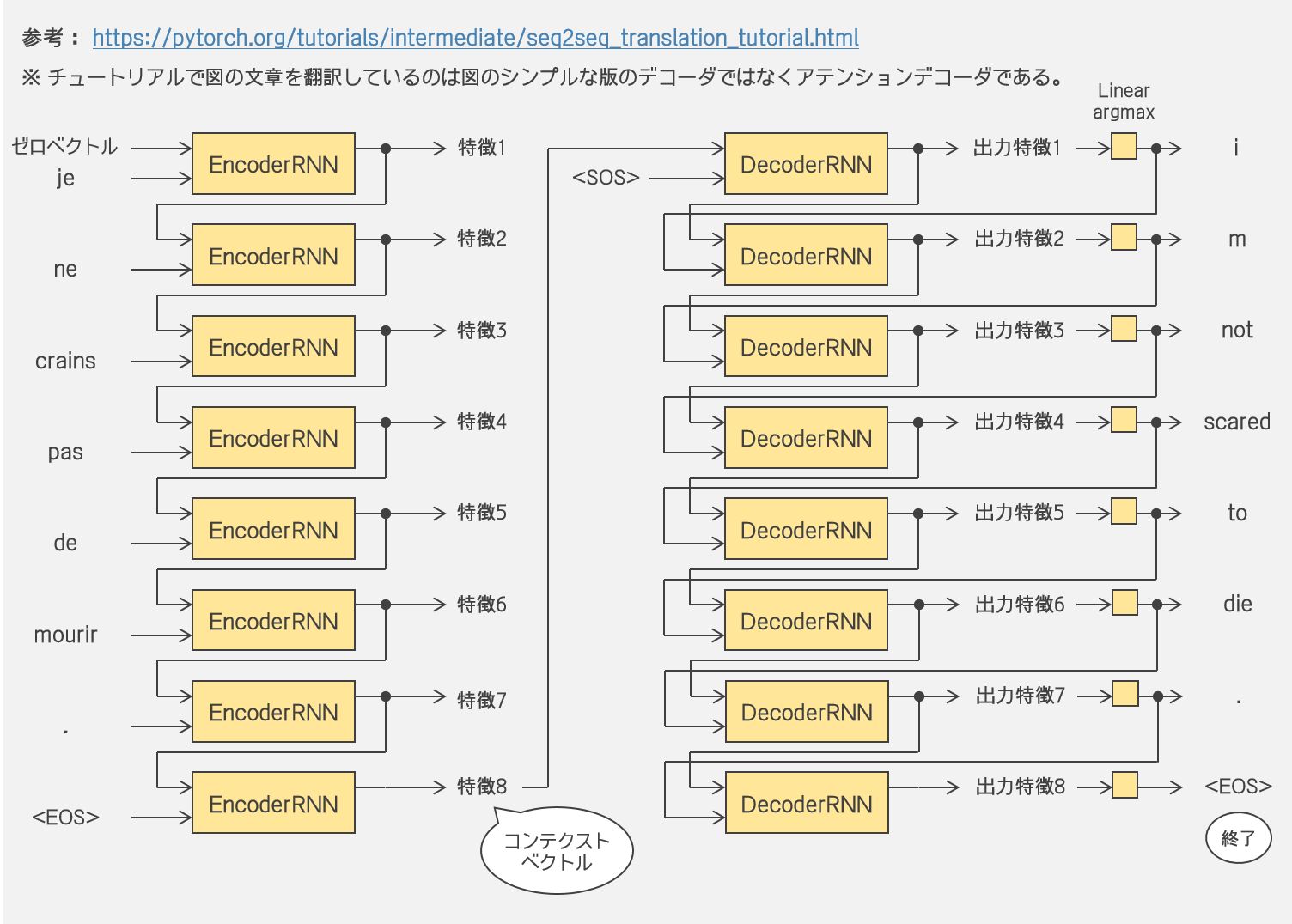
|
実際に翻訳をシミュレーションしてみましょう。無論、まだエンコーダもデコーダも学習していませんので、エンコードとデコードはでたらめです。その状態でデコーダが文末トークンを出すまでデコードを続けることはできませんので、デコーダから3単語まで取り出してみましょう。 |
In [8]:
print('◆ エンコーダに1つ目のデータを流してみる')
input_words = pairs[0][0].split(' ') + ['<EOS>']
(input_tensor, target_tensor) = tensorsFromPair(pairs[0])
print('\n◇ インプットデータ')
print(input_words)
print(input_tensor)
input_length = input_tensor.size(0)
hidden = encoder.initHidden()
for ei in range(input_length):
print('\n◇ 流す単語: ' + input_words[ei])
output, hidden = encoder.forward(input_tensor[ei], hidden, debug=True)
print('\n◇ コンテクストベクトル')
print(output.size(), output[:,:,:4])
print('\n\n◆ コンテクストベクトルをデコードしてみる')
input = torch.tensor([[SOS_token]], device='cpu')
for di in range(3):
print('\n◇ {}単語目を取り出す'.format(di + 1))
output, hidden = decoder.forward(input, hidden, debug=True)
topv, topi = output.data.topk(1)
print('デコード結果: {} --> {}'.format(topi.item(), output_lang.index2word[topi.item()]))
input = topi.squeeze().detach()
|
デコーダから順次単語が取り出されますが、無論意味のある文章にはみえませんね…。 |
アテンションデコーダの導入
|
でたらめのエンコーダとデコーダではまったく何もうれしくないですね。早く学習させたいです。どのように学習させるんです? |
|
あ、実際には上で導入したデコーダじゃなくてアテンション付きデコーダをつかうんだって。 |
|
アテンション? |
|
さっき導入したエンコーダとデコーダだと、エンコーダの最終ステップでの出力であるコンテキストベクトルが文章の情報を一身に背負わなければならなくて、負担が大きいらしい。だから、エンコーダの毎ステップの出力をすべてつかうことにする。 |
|
ええ…負担が大きいなら最初からそうすればよかったじゃないですか。…毎ステップの出力をすべてデコーダに突っ込むなら、もう GRU で再帰させなくてもいいのでは? 単に個々の単語をエンコードしてデコーダに渡せばいいでしょう? |
|
それは違うと思うかな。ある単語がどんな意味的な特徴をもつかは、やっぱり文脈に依存するよ。だから、単語を個別にエンコードするんじゃなくて、GRU で再帰させながら各ステップの特徴をつくるのは理に適っていると思う(このチュートリアルでは一方向だけど、逆方向からも再帰させたくなってくるね)。無論、ニューラルネットはどんな関数も表現してくれることが期待されるけど、だからといって各単語をばらばらにエンコードしたものをデコーダに丸投げじゃそれこそデコーダの負担が大きすぎると思うよ。 |
|
それは確かにそんな気も…では、アテンションとは何です? 日本語に訳すと「注意」ですか? 何に注意する必要があるというんです? |
|
デコード時に常にエンコーダの全てのステップの出力をつかうんだけど、実際は、最初の単語を出したいときに、文章全体の特徴をすべてつかいたいわけでもないってことだと思う。X 語から Y 語に翻訳するとき、もしかしたらこの2つの言語は文法が違って語順が違うかもしれないけど、Y 語に翻訳した文章の文頭に来るべき単語の意味は、元の X 語の文章の2番目の単語の意味に対応するとか、なんかそんな意味的な対応はあるはずなんだよね。その場合、最初の単語のデコード時には、エンコード時に2番目に吐き出された特徴だけに特に「注意」したい。その注意すべき箇所を指示するのがアテンション機構だね。注意すべきなのは1箇所とは限らないかもね。もしフランス語から翻訳するなら ne と pas の2箇所に注意することもあるかもしれないから。 |
|
なるほど…わかりましたよ! アテンションがうれしいのは、フランス語も英語も人間の自然言語だからですね? だって、フランス語を宇宙語に翻訳するのだったら、言葉の体系が違いすぎて、フランス語の何単語目に対応するかなんていうのが意味を成さないかもしれません。そのような場合は、やはり常に全てのステップの特徴を利用した方がいいでしょう? |
|
え、うん…そこまで概念が違う宇宙人の言葉だったら翻訳という行為が意味を成すのかもあやしいんじゃないかな…。 |
|
下図でいうと、いま何番目の単語に注意すべきかが「アテンションの重み」ですね。もしこのベクトル第1成分と第3成分が大きくなっていたら元の文章の1ステップ目と3ステップ目の特徴に注意せよということですか。それでその重みにしたがって特徴を抜き出して、それをここでは attn_combine と名付けた層で前回デコードした単語の表現に混ぜ込んでいますね? …これ、attn_combine せずに抜き出した特徴をそのまま GRU に突っ込むのでは駄目なんですか? GRU は結局「前回デコードした単語」「元文章の注目すべき位置の特徴」「現在未デコードのコンテクスト」を受け取って出力する特徴をつくるのでしょう? attn_combine しなくても同じであるように思うんですが。 |
|
attn_combine した上で活性化しているからモデルとして等価じゃないよ。…そうだな、これは全くあやしいイメージだけど、「前回デコードした単語」が「水」だったとして、「水」はいま「飲むもの」という特徴と「浴びるもの」という特徴をもっているとするよ。それで、「元文章の注目すべき位置の特徴」が、「飲み食いする」という特徴をもっているとする。このとき、「水」の「飲むもの」という特徴の方だけを活性化した状態で GRU に流したいんじゃないかな。 |
アテンション付きデコーダ
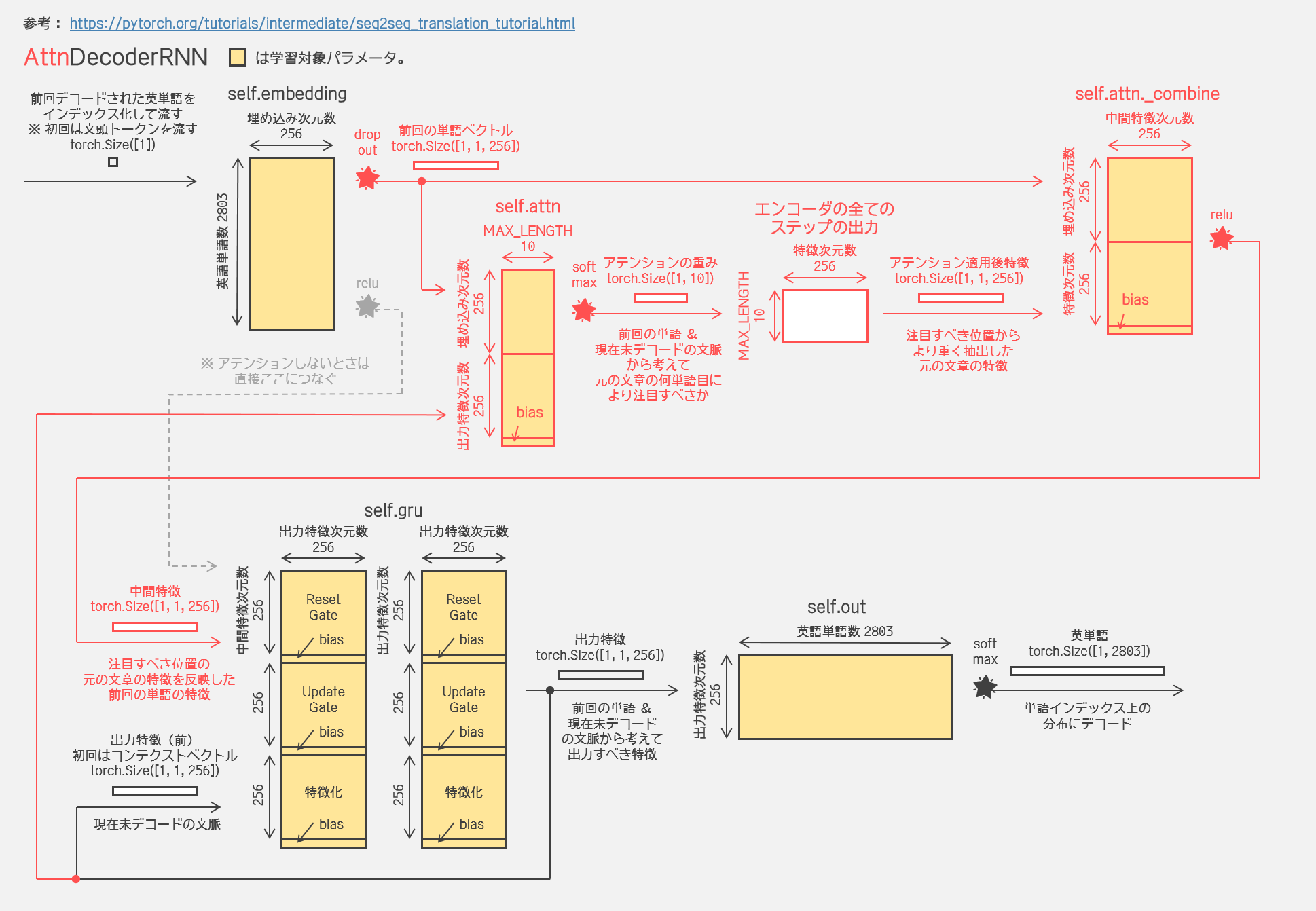
アテンション付きデコーダの場合の翻訳の流れ
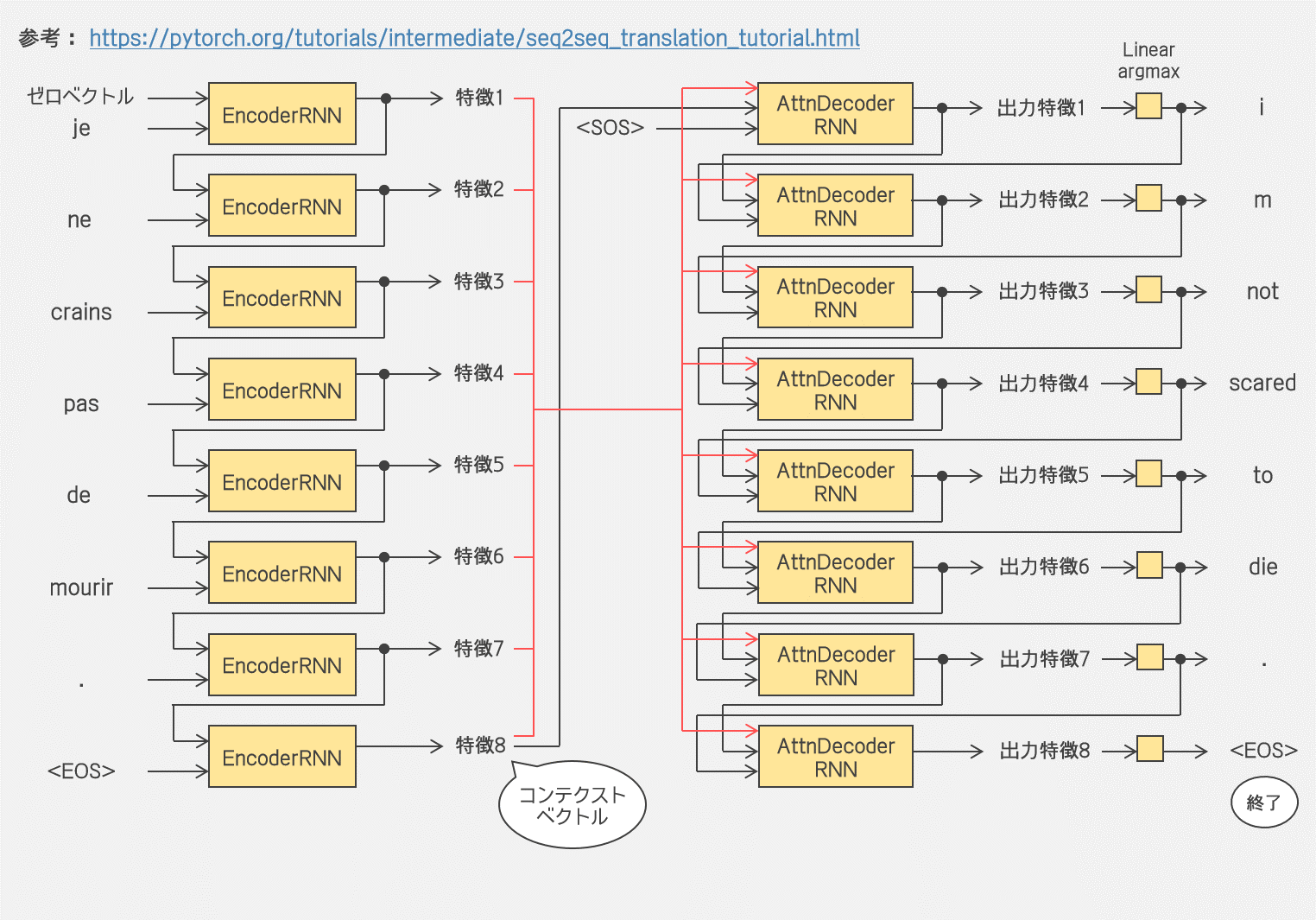
|
まあそれで、アテンション付きデコーダのコードは以下だね。元の文章のどこに注意するかをいつも計算するから、必然的に MAX_LENGTH を指定することが必要になるよ。forward メソッドが attn_weights も返しているけどこれは後々どこに注目しているか可視化したいからってだけだね。attn_weights を取り出しても次のステップでこれをまた入力するってことはないから。翻訳のシミュレーションもしてみるね。 |
In [9]:
import torch
import torch.nn as nn
from torch import optim
import torch.nn.functional as F
class AttnDecoderRNN(nn.Module):
def __init__(self, hidden_size, output_size, dropout_p=0.1, max_length=MAX_LENGTH):
super(AttnDecoderRNN, self).__init__()
self.hidden_size = hidden_size
self.output_size = output_size
self.dropout_p = dropout_p
self.max_length = max_length
self.embedding = nn.Embedding(self.output_size, self.hidden_size)
self.attn = nn.Linear(self.hidden_size * 2, self.max_length)
self.attn_combine = nn.Linear(self.hidden_size * 2, self.hidden_size)
self.dropout = nn.Dropout(self.dropout_p)
self.gru = nn.GRU(self.hidden_size, self.hidden_size)
self.out = nn.Linear(self.hidden_size, self.output_size)
def forward(self, input, hidden, encoder_outputs, debug=False):
if debug:
print('入力単語: ', input.size(), input)
print('入力特徴: ', hidden.size(), hidden[:,:,:3])
embedded = self.embedding(input).view(1, 1, -1)
embedded = self.dropout(embedded)
if debug:
print('埋め込み後 : ', embedded.size(), embedded[:,:,:3])
attn_weights = F.softmax(
self.attn(torch.cat((embedded[0], hidden[0]), 1)), dim=1)
if debug:
print('アテンションの重み: ', attn_weights.size(), attn_weights[:,:3])
print('アテンションを整形: ', attn_weights.unsqueeze(0).size())
print('エンコーダの全ステップの特徴を整形: ', encoder_outputs.unsqueeze(0).size())
attn_applied = torch.bmm(attn_weights.unsqueeze(0),
encoder_outputs.unsqueeze(0))
if debug:
print('アテンション適用後特徴: ', attn_applied.size(), attn_applied[:,:, :3])
output = torch.cat((embedded[0], attn_applied[0]), 1)
output = self.attn_combine(output).unsqueeze(0)
output = F.relu(output)
if debug:
print('中間特徴: ', attn_applied.size(), attn_applied[:,:, :3])
output, hidden = self.gru(output, hidden)
if debug:
print('GRUの出力 : ', output.size(), output[:,:,:3])
print('GRUの隠れ状態: ', hidden.size(), hidden[:,:,:3])
print('(単語を1つずつ流しているので出力と隠れ状態は一致)')
output = F.log_softmax(self.out(output[0]), dim=1)
return output, hidden, attn_weights
def initHidden(self):
return torch.zeros(1, 1, self.hidden_size, device='cpu')
hidden_size = 256
del decoder
decoder = AttnDecoderRNN(hidden_size, output_lang.n_words).to('cpu')
print('\n◆ アテンションデコーダの訓練対象パラメータ')
for name, param in decoder.named_parameters():
print(name.ljust(14), param.size())
print('\n\n◆ エンコーダに1つ目のデータを流してみる')
input_words = pairs[0][0].split(' ') + ['<EOS>']
(input_tensor, target_tensor) = tensorsFromPair(pairs[0])
print('\n◇ インプットデータ')
print(input_words)
print(input_tensor)
input_length = input_tensor.size(0)
encoder_hidden = encoder.initHidden()
encoder_outputs = torch.zeros(MAX_LENGTH, encoder.hidden_size, device='cpu')
for ei in range(input_length):
print('\n◇ 流す単語: ' + input_words[ei])
output, hidden = encoder.forward(input_tensor[ei], hidden, debug=True)
encoder_outputs[ei] += output[0, 0]
print('\n◇ 特徴ベクトル(全ステップ分)')
print(encoder_outputs.size())
print('\n\n◆ アテンションデコーダでデコードしてみる')
input = torch.tensor([[SOS_token]], device='cpu')
for di in range(3):
print('\n◇ {}単語目を取り出す'.format(di + 1))
output, hidden, decoder_attention = decoder.forward(input, hidden, encoder_outputs, debug=True)
topv, topi = output.data.topk(1)
print('デコード結果: {} --> {}'.format(topi.item(), output_lang.index2word[topi.item()]))
input = topi.squeeze().detach()
モデルの訓練
|
では、エンコーダとアテンション付きデコーダはどうやって訓練するのでしょう? まあ、翻訳をシミュレーションしてみたのでこうやって出てくる文章を正解の文章に寄らせていけばいいのはわかりますが、今回の場合、損失は何になるんでしょうか? |
|
損失としては単に各ステップの出力の交差エントロピー(F.log_softmax + nn.NLLLoss)を足し上げてるね。あと、訓練時に“Teacher forcing”ということもするみたい。 |
|
何ですかそれは? |
|
上のシミュレーションでもやったように、最初はでたらめな単語がデコードされてきちゃうよね。そうするとデコードの2ステップ目以降、前回の単語がでたらめな状態でデコードしていくことになっちゃって、これじゃなかなか学習が進まない。だから、確率的に前回の単語として正解の単語を入れちゃうってことらしい。そうすると収束が速いと。ただ反面、モデルが不安定になりやすいってある。カンニングしながら訓練しちゃってるようなものだしね…以下のチュートリアルのコードでは、正解の単語を入れる確率 teacher_forcing_ratio が 0.5 になっているけど、本当は徐々に下げていくものなんじゃないのかな…? 実際にはどうなんだろう…。 |
|
なるほど。「教師あり学習」というか、「教師がときどき代わりに回答を書き込んでくる学習」ですか。それで、以下の train が1対の文章ペアを入れてモデルを更新する関数ですね。 |
In [10]:
import random
teacher_forcing_ratio = 0.5
# 1対の文章ペアを入れてモデルを更新する関数
def train(input_tensor, target_tensor, encoder, decoder,
encoder_optimizer, decoder_optimizer, criterion,
max_length=MAX_LENGTH):
encoder_hidden = encoder.initHidden()
encoder_optimizer.zero_grad()
decoder_optimizer.zero_grad()
input_length = input_tensor.size(0)
target_length = target_tensor.size(0)
encoder_outputs = torch.zeros(max_length, encoder.hidden_size, device='cpu')
loss = 0
for ei in range(input_length):
encoder_output, encoder_hidden = encoder(
input_tensor[ei], encoder_hidden)
encoder_outputs[ei] = encoder_output[0, 0]
decoder_input = torch.tensor([[SOS_token]], device='cpu')
decoder_hidden = encoder_hidden
use_teacher_forcing = True if random.random() < teacher_forcing_ratio else False
if use_teacher_forcing:
# デコードの2ステップ目以降、前ステップの単語として正解の単語を利用する
for di in range(target_length):
decoder_output, decoder_hidden, decoder_attention = decoder(
decoder_input, decoder_hidden, encoder_outputs)
loss += criterion(decoder_output, target_tensor[di])
decoder_input = target_tensor[di] # Teacher forcing
else:
# デコードの2ステップ目以降、前ステップの単語としてモデルが予測した単語を利用する
for di in range(target_length):
decoder_output, decoder_hidden, decoder_attention = decoder(
decoder_input, decoder_hidden, encoder_outputs)
topv, topi = decoder_output.topk(1)
decoder_input = topi.squeeze().detach() # detach from history as input
loss += criterion(decoder_output, target_tensor[di])
if decoder_input.item() == EOS_token:
break
loss.backward()
encoder_optimizer.step()
decoder_optimizer.step()
return loss.item() / target_length
|
以下の trainIters がたくさんの文章ペアに対して学習を回す関数ですね。ここでは n_iters を 75000 にしていますが、いま訓練対象の文章ペアは 10599 ですから、1つの文章が 7, 8 回選ばれている計算になりますね。…訓練する文章はランダムに選ばれていますが、短い文章から長い文章に向かって学習すると上手くいくなどはないのでしょうか? 人間の幼児も2語文、3語文から覚え始めると思いますし…しかし、それでは学習の序盤に短い文章にフィットしてしまうのでしょうか?? |
In [11]:
import time
import math
%matplotlib inline
import matplotlib.pyplot as plt
plt.switch_backend('agg')
import matplotlib.ticker as ticker
import numpy as np
def asMinutes(s):
m = math.floor(s / 60)
s -= m * 60
return '%dm %ds' % (m, s)
def timeSince(since, percent):
now = time.time()
s = now - since
es = s / (percent)
rs = es - s
return '%s (- %s)' % (asMinutes(s), asMinutes(rs))
def showPlot(points):
plt.figure()
fig, ax = plt.subplots()
# this locator puts ticks at regular intervals
loc = ticker.MultipleLocator(base=0.2)
ax.yaxis.set_major_locator(loc)
plt.plot(points)
def trainIters(encoder, decoder, n_iters, print_every=1000, plot_every=100, learning_rate=0.01):
start = time.time()
plot_losses = []
print_loss_total = 0 # Reset every print_every
plot_loss_total = 0 # Reset every plot_every
encoder_optimizer = optim.SGD(encoder.parameters(), lr=learning_rate)
decoder_optimizer = optim.SGD(decoder.parameters(), lr=learning_rate)
training_pairs = [tensorsFromPair(random.choice(pairs))
for i in range(n_iters)]
criterion = nn.NLLLoss()
for iter in range(1, n_iters + 1):
training_pair = training_pairs[iter - 1]
input_tensor = training_pair[0]
target_tensor = training_pair[1]
loss = train(input_tensor, target_tensor, encoder,
decoder, encoder_optimizer, decoder_optimizer, criterion)
print_loss_total += loss
plot_loss_total += loss
if iter % print_every == 0:
print_loss_avg = print_loss_total / print_every
print_loss_total = 0
print('%s (%d %d%%) %.4f' % (timeSince(start, iter / n_iters),
iter, iter / n_iters * 100, print_loss_avg))
torch.save(encoder.state_dict(), 'eng-fra-encoder')
torch.save(decoder.state_dict(), 'eng-fra-decoder')
if iter % plot_every == 0:
plot_loss_avg = plot_loss_total / plot_every
plot_losses.append(plot_loss_avg)
plot_loss_total = 0
showPlot(plot_losses)
hidden_size = 256
encoder1 = EncoderRNN(input_lang.n_words, hidden_size).to('cpu')
attn_decoder1 = AttnDecoderRNN(hidden_size, output_lang.n_words, dropout_p=0.1).to('cpu')
import os
# 既に学習済みの場合はモデルをロード(学習には cpu で1時間かかった)
if os.path.isfile('eng-fra-encoder') and os.path.isfile('eng-fra-decoder'):
encoder1.load_state_dict(torch.load('eng-fra-encoder'))
attn_decoder1.load_state_dict(torch.load('eng-fra-decoder'))
else:
trainIters(encoder1, attn_decoder1, 75000, print_every=5000)
訓練結果
|
訓練したモデルにフランス語の文章を読み込ませてみると、そこそこの確率でぴったり正解の英文に翻訳してくれますね。しかし、今回は全てのデータをランダムに利用して学習していますから、これらは訓練データに含まれていた可能性も高いですね…。 |
In [12]:
def evaluate(encoder, decoder, sentence, max_length=MAX_LENGTH):
with torch.no_grad():
input_tensor = tensorFromSentence(input_lang, sentence)
input_length = input_tensor.size()[0]
encoder_hidden = encoder.initHidden()
encoder_outputs = torch.zeros(max_length, encoder.hidden_size, device='cpu')
for ei in range(input_length):
encoder_output, encoder_hidden = encoder(input_tensor[ei], encoder_hidden)
encoder_outputs[ei] += encoder_output[0, 0]
decoder_input = torch.tensor([[SOS_token]], device='cpu') # SOS
decoder_hidden = encoder_hidden
decoded_words = []
decoder_attentions = torch.zeros(max_length, max_length)
for di in range(max_length):
decoder_output, decoder_hidden, decoder_attention = decoder(
decoder_input, decoder_hidden, encoder_outputs)
decoder_attentions[di] = decoder_attention.data
topv, topi = decoder_output.data.topk(1)
if topi.item() == EOS_token:
decoded_words.append('<EOS>')
break
else:
decoded_words.append(output_lang.index2word[topi.item()])
decoder_input = topi.squeeze().detach()
return decoded_words, decoder_attentions[:di + 1]
def evaluateRandomly(encoder, decoder, n=10):
for i in range(n):
pair = random.choice(pairs)
print('>', pair[0])
print('=', pair[1])
output_words, attentions = evaluate(encoder, decoder, pair[0])
output_sentence = ' '.join(output_words)
print('<', output_sentence)
print('')
evaluateRandomly(encoder1, attn_decoder1)
|
このチュートリアルではアテンションの可視化もしているね(以下)。 |
In [13]:
def showAttention(input_sentence, output_words, attentions):
# Set up figure with colorbar
fig = plt.figure()
ax = fig.add_subplot(111)
cax = ax.matshow(attentions.numpy(), cmap='bone')
fig.colorbar(cax)
# Set up axes
ax.set_xticklabels([''] + input_sentence.split(' ') +
['<EOS>'], rotation=90)
ax.set_yticklabels([''] + output_words)
# Show label at every tick
ax.xaxis.set_major_locator(ticker.MultipleLocator(1))
ax.yaxis.set_major_locator(ticker.MultipleLocator(1))
plt.show()
def evaluateAndShowAttention(input_sentence):
output_words, attentions = evaluate(
encoder1, attn_decoder1, input_sentence)
print('input =', input_sentence)
print('output =', ' '.join(output_words))
showAttention(input_sentence, output_words, attentions)
evaluateAndShowAttention("elle a cinq ans de moins que moi .")
evaluateAndShowAttention("elle est trop petit .")
evaluateAndShowAttention("je ne crains pas de mourir .")
evaluateAndShowAttention("c est un jeune directeur plein de talent .")




|
このチュートリアルではアテンションの可視化もしているね(以下)。…これをみると、not を読みだすときに注目しているのは ne/pas の両方じゃなくて pas だけだなあ…。形容詞の前置修飾と後置修飾はどうだろう。 |
In [16]:
evaluateAndShowAttention("c est un employe de bureau .")

|
これでもアテンションの重みが大きいマスは概ね対角線上に並んでいるなあ…。アテンションは意味の対応する語に注目するわけではないのか、今回が訓練データに過学習なのかなあ…。 |
|
ええ…。 |
|
チュートリアルの最後には Exercises として、別の言語間の翻訳機にしてみようとか、会話応答などを学んでみようとか、学習済みの単語埋め込みをつかってみようとか、層数を変えてみようとか、入出力を同一にしてオートエンコーダを学習した後デコーダだけ新しく学習しようとかあるね。最後のはどう変わるんだろう? |
おわり
In [ ]: